
How to use AI with your own legal knowledge: A practical guide for law firms and in-house teams
The effectiveness of AI drafting tools in law depends entirely on the quality of the knowledge behind them. Here’s what works – and what doesn’t – when you ground AI in your own legal expertise.
TL;DR
- Generic AI models don’t know your firm’s standards, precedents, or playbook positions – you need to connect them to your own knowledge to get consistent, defensible output.
- There are five main approaches: direct prompting, structured knowledge bases, fine-tuning, semantic search (RAG), and live database integration.
- Fine-tuning is widely hyped but often disappoints for legal knowledge use cases.
- The most effective approach right now combines a well-curated clause library with semantic retrieval – and the best tools handle this automatically inside Microsoft Word.
- Your knowledge base is the asset. The AI model is the engine. Clean knowledge in, quality drafts out.
The problem: AI doesn’t know what you know
Most lawyers have seen what a capable AI model can do – draft a clause, redline a contract, and summarize a document in seconds. The demos are impressive.
But there’s a question that comes up in almost every serious conversation about deploying AI in a legal team – whether at a law firm or in an in-house department:
“Can it use our own precedents and playbooks, or does it only know generic legal language?”
It’s the right question to ask. Large language models (LLMs) like GPT-4 were trained on enormous volumes of publicly available text – US case law, EU legislation, contract structures, legal terminology. That’s why they can draft surprisingly competent clauses from scratch.
But that training has hard limits. Local legislation, jurisdiction-specific case law, non-English legal frameworks, and specialized practice areas are underrepresented. More critically, your specific institutional knowledge doesn’t exist in any public training data at all – whether that’s a law firm’s partner-developed drafting standards and client-specific playbooks, or an in-house team’s preferred fallback positions, approved NDA templates, and negotiation redlines.
The AI has never seen any of it. This isn’t a flaw – it’s simply how these models are built. The question is how to bridge that gap effectively.
What “grounding AI in your own knowledge” means
Grounding is the practice of providing an AI model with relevant, specific context: your clauses, precedents, playbooks, and standards – so the outputs reflect your institutional expertise rather than a generic average of publicly available legal language.
For a law firm, that means the AI drafts in the style and to the standards your partners have developed, using your preferred fallback positions and firm-approved clause variants – not something plucked from the general internet. For an in-house team, it means AI that reflects your negotiating positions, your risk appetite, and the specific commercial context of your organization –not a generic corporate template.
What AI for law firms and in-house legal teams needs to do
There are five main approaches to grounding AI in your own knowledge. They vary significantly in cost, complexity, and how well they actually work in practice.
Method 1: Direct prompting – fast, flexible, limited in scale
What it is: Paste relevant text directly into the prompt alongside your question or instruction.
Why it matters for law firms: When a fee earner is working on a specific matter, they can paste the firm’s preferred clause or a relevant precedent into the prompt and ask the AI to adapt it. The AI works within your language and structure rather than generating something generic. For individual, ad-hoc tasks this is fast and effective – no setup required.
Why it matters for in-house teams: For a lawyer reviewing a counterparty draft, this approach lets them quickly ground the AI in their playbook position on a specific clause type before asking it to suggest redlines. It’s practical for one-off tasks but creates inconsistency at scale – different lawyers will include different precedents and get different outputs.
The limitation: Context windows are far less restrictive than they were two years ago. GPT-4o supports 128,000 tokens, roughly 90,000 words, and GPT-4.1 extends to 1 million tokens. The constraint is no longer whether material fits, but whether the AI uses the right material. Feeding in everything doesn’t guarantee the most relevant clause gets prioritized. The better tools handle this for you. Surfacing the right precedents automatically based on what you’re drafting, making direct prompting practical at scale without requiring each lawyer to be an expert prompt engineer.
Method 2: A structured knowledge base – the highest-leverage investment for law firms and in-house teams
What it is: A curated, searchable library of your best clauses, templates, playbooks, and precedent contracts that AI can draw from consistently across your entire team.
Why it matters for law firms: Institutional knowledge in most firms exists in the heads of senior partners and in an unstructured pile of past deals. When partners leave, that knowledge walks out the door. When junior associates draft, they may not know which precedent is current or what the firm’s preferred position is. A structured knowledge base makes the firm’s collective expertise available to every fee earner on every matter – consistently and at scale.
“LawVu Draft covers the whole topic of knowledge management. That means you have your own clause libraries with your own templates. With AI, you can rewrite them and edit them, and when you are drafting new contracts, you don’t have to start from scratch.”
Dr Frederik Leenen, Head of Legal Tech at CMS
Why it matters for in-house teams: In-house legal teams typically have a similar problem – knowledge technically exists, but it’s buried in a vast, unstructured collection of old contracts, Excel files, and Word documents. Axel Springer’s legal team described it precisely:
“We’ve always had a huge, unstructured pile of precedent documents to search for good clauses in. But it’s hard to find good needles in a haystack like that.”
Their solution – using LawVu Draft to extract clauses from their precedent database and elevate them into a curated library – reflects the model that works for both audiences: structured, searchable knowledge that AI can use, accessible directly inside Word without switching systems.
The investment is the same for both: committing to knowledge curation as a core operational priority, not a background task. The return is also the same: AI outputs that reflect your actual standards rather than a generic baseline.
Method 3: Fine-tuning – promising in theory, underwhelming in practice
What it is: Taking an existing AI model and training it further on your own data – your memos, contracts, legal opinions – to create a version that reflects your team’s knowledge and style.
Why it matters for law firms: The appeal is obvious: a model that drafts in the style and to the standards your partners have developed over years, without needing to manually provide context every time. In theory, fine-tuning could encode a firm’s preferred drafting approach and reduce the burden on individual fee earners to know which precedent to use.
Why it matters for in-house teams: Similarly, an in-house team might want a model that already knows their standard NDA positions, their risk appetite on limitation of liability, or their preferred governing law clauses – without needing to paste those positions in on every interaction.
The limitation: Fine-tuning is unreliable for factual knowledge recall – which is precisely what law firms and in-house teams need most. The model may appear to have learned your positions, but it will still hallucinate or blend your specific standards with generic training data in unpredictable ways. OpenAI’s own documentation notes that fine-tuning is better suited to teaching tasks than instilling factual knowledge. Training costs have dropped significantly – fine-tuning GPT-4o mini now runs around $3 per million training tokens – but the ongoing inference costs for fine-tuned models remain higher than standard models. And fine-tuning typically has to be repeated from scratch each time your playbook positions change or significant new precedent is added. For a legal team across multiple practice areas and jurisdictions, recurring overhead adds up. The fundamental reliability problem for factual recall remains regardless of price.
Method 4: Semantic search (RAG) – the most practical solution available today
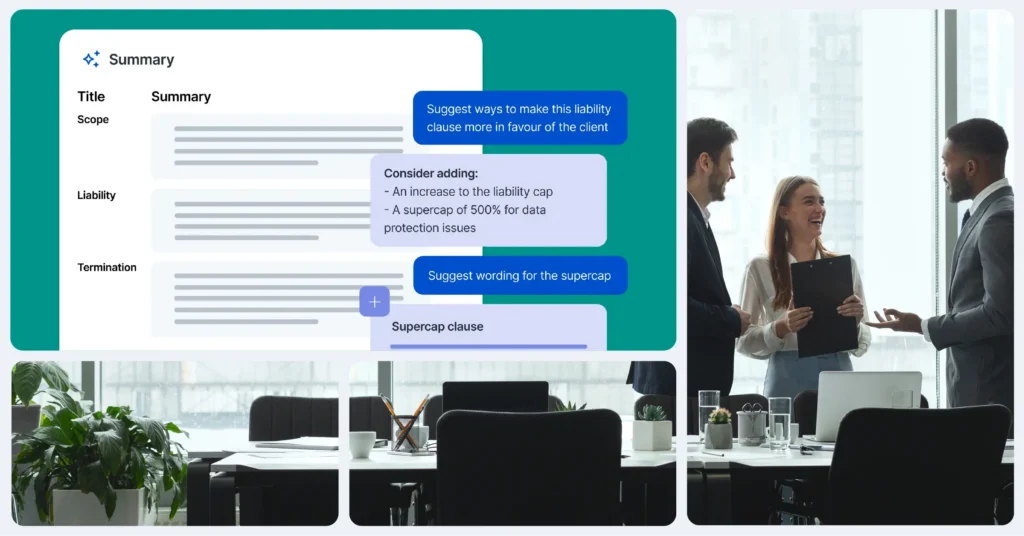
What it is: Retrieval-Augmented Generation (RAG) combines a well-organized knowledge base with semantic search and AI generation. Rather than trying to teach the AI what you know, you retrieve the most relevant precedents and positions at the moment the AI needs them, and provide those as context.
How it works in practice: When a fee earner is drafting a warranty clause in an M&A deal, the system searches the firm’s knowledge base – not just for exact keyword matches, but semantically, finding content that’s meaningfully related. It surfaces the firm’s standard warranty positions, relevant precedents from comparable transactions, and any applicable playbook language. That material is fed to the AI alongside the drafting instruction, and the output reflects the firm’s actual standards. For an in-house team reviewing a counterparty NDA, the same principle applies – the system retrieves your approved fallback positions and preferred language, so the AI’s suggested redlines reflect your negotiating stance.
Why it works better than fine-tuning for most legal use cases:
- Your knowledge base is easy to update – add a new precedent or revise a playbook position and it’s immediately reflected in future outputs, without retraining
- Access controls work naturally – a law firm can restrict which practice group’s precedents are accessible for which matter types; an in-house team can limit access by department or geography
- The output is auditable – you can see exactly which precedents the AI drew from, which matters for both client file management and internal compliance
SD Worx moved from managing their clause structure in Excel files and Word documents to a centralized system precisely because the old approach couldn’t scale. Chief Legal and Compliance Officer Fabienne Lallemand noted that LawVu Draft now “allows our in-house lawyers to centrally manage contracts and make them available in an intelligent, user-friendly way to colleagues who need them – streamlining the operation between the legal department and the rest of the company.”
CMS took the same approach for different reasons – bringing consistency and institutional knowledge access to every fee earner across their firm, rather than leaving it dependent on who happened to have worked on a similar deal before.
Method 5: Live knowledge base integration – AI with dynamic access to your library
What it is: Rather than pre-selecting context before each interaction, the AI has dynamic access to your knowledge base as a queryable resource – reaching into your library on demand when it needs a specific clause type, precedent, or playbook position.
For law firms: This means an associate drafting a facility agreement can get AI suggestions that draw on the firm’s latest banking precedents automatically, without a partner needing to point them to the right documents first. The firm’s knowledge becomes self-distributing.
For in-house teams: A lawyer reviewing an incoming vendor contract gets AI-suggested redlines that automatically reflect the company’s current approved positions – not last year’s playbook that someone may or may not have updated.
The trade-off: The AI is making decisions about what to retrieve, which requires trusting its judgment about relevance. Human oversight remains important – the reviewing lawyer needs to understand where suggestions came from and whether the retrieved precedents are appropriate for the specific situation. This is especially true in law firm settings where client-specific instructions or matter-specific context can override standard positions.
What this means in practice
Three things hold true whether you’re a law firm or an in-house team:
Your knowledge base is the asset, not the AI model. The models available are broadly capable. What differentiates outcomes is the quality and organization of the institutional knowledge those models work with. For law firms, that means capturing and structuring the contract standards partners have developed over careers. For in-house teams, it means converting scattered precedents and informal playbook knowledge into something a system can actually use.
Structured knowledge pays compound dividends. Every clause a fee earner pulls from a past deal and adds to the library makes the next draft faster and more consistent. Every playbook position an in-house team documents becomes instantly available to every lawyer who touches a related contract – no hunting, no guessing, no reinventing. The teams building this foundation now aren’t just saving time today; they’re creating an institutional knowledge asset that gets more valuable with every matter they work on.
Adoption depends on where the tool lives. CMS noted that LawVu Draft saw unusually strong adoption – including lawyers who typically resist new technology – precisely because it feels like an augmentation of what they already do rather than a replacement. As Dr Leenen said: “It feels much more like an augmentation of what lawyers have been doing rather than a replacement or a complete change of everything.” That observation applies equally to law firm associates and in-house counsel. The AI needs to live inside Microsoft Word – where legal work actually happens – to get used consistently.
The bottom line
AI’s ability to work with legal language is genuinely impressive and improving quickly. Its the inability to apply your specific institutional knowledge – your firm’s standards, your team’s positions, your jurisdiction-specific expertise – that creates risks and problems, and this is the matters most for producing work that meets your standards rather than a generic baseline.
The legal teams getting the most from AI right now, whether law firms or in-house departments, aren’t the ones with the most sophisticated models. They’re the ones who have invested in organizing their knowledge so AI can use it effectively. Clean knowledge in, quality contracts out.
The reverse is equally true.
Knowledge management has historically been a weak area across the legal profession. That’s changing fast – because AI makes the cost of poor knowledge of an organization visible in every draft, every review, and every negotiation.
